Source Coding¶
In this chapter we take a look at the basic principles and algorithms for data compression.
1The role of coding¶
In the general block diagram of a communication system, the coding block is situated between the information source and the communication channel.
 {width=35%}
{width=35%}
It’s role is to prepare the raw information in order to be transmitted over the channel. It has two main jobs:
Source coding:
Convert source messages to channel symbols, i.e. the actual symbols which the channel knows to transmit.
For example, express the messages in binary form (zeros and ones), for sending over a binary channel.
Minimize the number of symbols needed to be transmitted (i.e., data compression). We don’t want to transmit more symbols than necessary to recover the messages at the receiving end.
Adapt probabilities of symbols in order to maximize to maximize mutual information. We will discuss this more in Chapter IV.
Error control coding
Protect the information against channel errors
Also known as “channel coding”
Basically, source coding refers to all the procedures required to express the source messages as channel symbols in the most efficient way possible, while error control coding refers to all the algorithms used to protect the data against errors.
The coding block has a corresponding decoding block on the receiving end. Its job is to “undo” all the coding operations:
detect and fix the errors in the received data, based on the algorithms introduced by the coding block
convert the channel symbols back into the message representations that the receiver expects
Is it possible to do these two jobs separately, one after another, in two consecutive operations? Yes, as the source-channel separation theorem establishes.
We give below only an informal statement of the theorem:
In this chapter, we consider only the source coding algorithms, without any error control. Basically, we assume that data transmission is done over an ideal channel with no noise, and therefore the transmitted symbols are perfectly recovered at the receiver.
In this context, our main concern is how to minimize the number of symbols needed to represent the messages, while making sure that the receiver can decode the messages correctly. The advantages of data compression are self-evident:
Efficiency
Short communication times
Can decode easily
2Definitions¶
Let’s define what coding means from a mathematical perspective.
Consider an input information source with the set of messages:
and suppose we would like to express the messages as a sequence of the following code symbols:
The set is known as the alphabet of the code.
For example, for a binary code we have and a possible sequence of symbols is
The codewords are the sequences of symbols used by the code.
The codeword length, which we denote as , is the the number of symbols in a given codeword .
Encoding a given message or sequences of messages means replacing each message with its codeword.
Decoding means deducing back the original sequence of messages, given a sequence of symbols.
As an example, the ASCII code is a widely-used code for encoding characters, consisting of 256 codewords (stored on 1 byte):
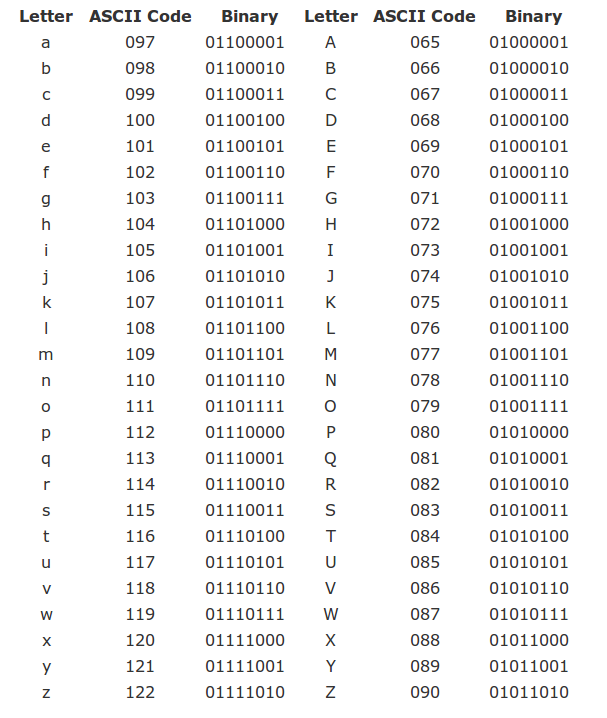
Nowadays, ASCII is usually replaced by Unicode (UTF-8), which is a more general code using 65536 codewords (stored on 2 bytes), allowing for many more letters used in languages around the globe.
2.1The graph of a code¶
The codewords of a code can represented as a binary tree. We call this representation the graph of the code.
TODO: Example at blackboard
2.2Average code length¶
There are many ways to define the codewords for messages, but some are better than others.
The most basic quantity indicating efficiency of a code is the average code length.
For every codeword , we multiply the probability of the corresponding message with its length .
A code with smaller average length is better, because it represents sequences of messages with less symbols, on average. However, there is a certain lower limit to how small the average length can be (for example, it cannot be 0, for self-evident reasons).
This raises the following interesting question:
Given a source , how small can the average length be?
This is a fundamental question, to which we will provide an answer later in this chapter.
2.3Instantaneous codes¶
We introduce another set of useful definitions regarding the codeword structure.
A code can be:
non-singular: all codewords are different
uniquely decodable: no two sequences of messages translate to the same sequence of symbols
i.e. there is never a confusion at decoding: there can be only one sequence of messages corresponding to a given sequence of symbols
instantaneous (also known as prefix-free): no codeword is prefix to another code
A prefix = a codeword which is the beginning of another codeword
Examples: at the blackboard
The follwing relations exist between these types of codes.
We can summarize the relation between these three code types as follows:
Instantaneous uniquely decodable non-singular
Graph-based decoding of instantaneous codes¶
Using the graph of the code, we can use a very simple procedure for decoding any instantaneous code:
TODO: TBD: Illustrate at whiteboard
This procedure shows the advantage of instantaneous codes over other codes which might be uniquely decodable, but are not instantaneous. Instantaneous codes allow for simple decoding. There is never any doubt about the next message in the sequence.
This decoding scheme is also showing why these codes are named “instantaneous”: a codeword can be decoded as soon as it is fully received, immediately, without any delay, because the decoding takes place on-the-fly while the bits are received one-by-one.
As a counter example, consider the following uniquely decodable, but non-instantaneous code: . When you read the first 0, you cannot decode it yet, because you need to wait the next bits to understand how to segment the sequence. This implies that the decoding has some delay.
3The Kraft inequality theorem¶
When can an instantaneous code exist? Given a DMS , are we sure we can find an instantaneous code for it, and if yes, under which conditions?
The answers to these questions is provided by the Kraft inequality.
Comments on the Kraft inequality:
If lengths do not satisfy the relation, no instantaneous code exists with these lengths
If the lengths of a code satisfy the relation, that code can be instantaneous or not (there exists an instantaneous code, but not necessarily that one). Keep in mind that the Kraft inequality only looks at the lengths of the codewords, not at their actual symbols, so it can only say something about the lengths, not about the actual codewords
The Kraft inequality implies that the codewords lengths cannot be all very small, because if all values are too small the sum exceeds 1. Thus, implicitly, it sets a lower limit to the permissible lengths.
From the proof, it follows that we have equality in the relation
only if the lowest level of the tree is fully covered. Thus, for an instantaneous code which satisfies Kraft with equality, all the graph branches terminate with codewords and there are no unused branches.
This makes sense intuitively, since is most economical way: codewords are as short as they can be. Any unused branch means that we can actually make the code shorter by moving some message up the tree.
We have seen that instantaneous codes must obey the Kraft inequality But how about uniquely decodable codes? The answer is given by the next theorem.
Consequences of the McMillan theorem:
For every uniquely decodable code, there exists in instantaneous code with the same lengths. This is because the lengths must satisfy the same relation both for unique-decodable and for instantanous codes.
Thus, even though the class of uniquely decodable codes is larger than that of instantaneous codes (because any instantaneous code is uniquely decodable, but not any uniquely decodable code is instantaneous), using uniquely-decodable codes brings no additional benefit in average codeword length
Instead of an uniquely decodable code, we can always use an instantaneous code, which has the same lengths, but is much easier to decode.
3.1Finding an instantaneous code for given lengths¶
How to find codewords with code lengths ?
In general, we may use the following procedure:
Note that this procedure only gives us the codewords, not the mapping to a particular set of messages.
In practice, there might be more elaborate ways to find the codewords and map them to the messages of the source, with additional benefits.
4Minimum average length¶
We will discuss now one of the most important aspect of this chapter,
Given a DMS , suppose we want to find an instantenous code for it, but in such a way as to minimize the average length of the code:
How can we find such an optimal code?
Given that it should be instantaneous, the codeword lengths must obey the Kraft inequality.
In mathenatical terms, we formulate the problem as a constrained optimization problem:
This means that we want to find the unknowns in order to minimize a certain quantity (), but the unknowns must satisfy a certain constraint ().
4.1The method of Lagrange multipliers¶
To solve this problem, we use a standard mathematical tool known as the method of Lagrange multipliers.
Let’s use this mathematical formulation to our problem. In our case, the functions and the variables involved are the following:
The unknowns are the lengths
The function to minimize is
The constraint is
The resulting optimal codeword lengths are:
The fundamental interpretation of this result is that, in order to minimize the average length of a code, a message with higher probability must have a shorter codeword, while a message with lower probability must have a longer codeword. This makes sense because messages we can afford to use a longer codeword for messages which appear rarely in a sequence.
4.2Entropy is the limit¶
Another fundamental consequence of the preceding theorem gives us a functional definition of the entropy, i.e. it tells us what the entropy really says about an information source.
Assume we have a binary code (we choose it binary in order to match the choice of in the definition of entropy).
Since the optimal codeword lenghts are , then the minimal average length obtainable is equal the entropy of the source:
This result tells us what the entropy really means, besides the algebric definition provided in chapter I. The entropy gives us the minimum number of bits required to represent the data generated by an information source in binary form. Although we rigorously proved this result only for a discrete memoryless source, it holds for sources with memory as well.
Some immediate consequences:
Messages from a source with small entropy can be written (encoded) with few bits
A source with with large entropy requires more bits for encoding the messages
Reformulating this in a different way, we can say that he average length of an uniquely decodable code must be at least as large as the source entropy. One can never represent messages, on average, with a code having average length less than the entropy.
Efficiency and redundancy of a code¶
Considering a code for an information source, comparing the average code length with the entropy indicates the efficiency of the encoding. These quantities indicate how close is the average length to the optimal value.
Coding with the wrong code¶
An interesting question arises in practice. Consider a source with probabilities . We design a code for this source, but we use it to encode messages from a different source, with probabilities .
This happens in practice when we estimate the probabilities from a sample data file, and then we use the code for general of similar files. Those files might not have exactly the same frequencies of messages as the sample file used to design the code.
How does this affect us? We lose some efficiency, because the codeword lengths are not optimal for the source with probabilities , which leads to increased average length.
If the codewords were optimal, the codeword lengths would have been , leading to an average length equal to the entropy :
But the actual average length we obtain is:
The difference between average lengths is what we lose due to the mismatch:
The difference is exactly the Kullback-Leibler distance between the two distributions and .
Therefore we have a functional definition of the KL distance: the KL distance between two distributions and is the number of extra bits spent when we encode messages from using a code optimized for a different distribution .
Due to the KL distance properties, the distance is always , which shows that such a mismatch always increases the average length. The more different the two distributions are, the larger the increase in average length becomes.
5Coding procedures¶
5.1Optimal and non-optimal codes¶
A code for which is known as an optimal code. Such a code attains the minimum average length:
However, this is only possible if the probabilities are powers of 2, such that is an integer number, because the codeword lengths must always be natural numbers.
e.g. probabilities like , , , known as dyadic distribution
the lengths are all natural numbers
An optimal code can always be found for a source where all are powers of 2, using for example the graph-based procedure explained earlier.
However, in the general case might not be an integer number. This happens when is not a power of 2. What to do in this case?
A simple solution to this problem is to round every logarithm to next largest natural number:
for example:
This leads to the Shannon coding algorithm described below.
5.2Shannon coding¶
The Shannon coding procedure is a simple algorithm for finding an instantaneous code for a DMS.
The code obtained with this procedure is known as a Shannon code.
Shannon coding is one of the simplest algorithms, and some other better schemes are available. However, this simplicity allows to prove fundamental results in coding theory, as we shall see below.
One such fundamental result shows that the average length of a Shannon code is actually close to the entropy of the source.
Although a Shannon code is not optimal, in the sense that it does not lead to the minimum achievable average length, we see that it’s also not very bad. The average length of Shannon code is at most 1 bit longer than the minimum possible value, which is quite efficient. However, better procedures do exist.
5.3Shannon’s first theorem¶
Shannon’s first theorem (coding theorem for noiseless channels) shows us that, in theory, we can approach the entropy as close as we want, using extended sources.
The theorem shows that, in principle, we can always obtain , if we consider longer and longer sequences of messages from the source, modeled as larger and larger extensions of the source.
However, this result is mostly theoretical, because in practice the size of gets too large for large . Other (better) algorithms than Shannon coding are used in practice to approach .
5.4Shannon-Fano coding (binary)¶
The Shannon-Fano (binary) coding procedure is presented below.
It’s easier to understand the Shannon-Fano coding by looking at an example at the whiteboard, or at a solved exercise.
Shannon-Fano coding does not always produce the shortest code lengths, but in general it is better than Shannon coding in this respect.
As a remark, there is a clear connection between Shannon-Fano coding and the optimal decision tree examples from the first chapter (with yes-no answers). Splitting the messages into two groups is similar to splitting the decision tree into two branches.
5.5Huffman coding (binary)¶
Huffman coding produces a code with the smallest average length (better than Shannon-Fano). It can be proven (though we won’t give the proof here) that no other algorithm which assigns a separate codeword for each message can produce a code with smaller average length than Huffman coding. Some better algorithms do exist, but they work differently: they do not assign a codeword to every single message, instead they code a whole sequence at once.
Assigning 0 and 1 in the backwards pass can be done in any order. This leads to different codewords, but with the same codeword lengths, so the resulting codes are equivalent.
When inserting a sum into an existing list, it may be equal to another value(s), so we may have several options where to insert: above, below or in-between equal values. This leads to codes with different individual lengths, but same average length. In general, if there are several options available, it is better to insert the sum as high as possible in the list, because this leads to a more balanced tree, and therefore the codewords tend to have more equal lengths. This is helpful in practice in things like buffering. Inserting as low as possible tends to produce codewords with more widely varying lengths, which increases the demands on the buffers.
5.6Huffman coding (M symbols)¶
All coding procedures can be extended to the general case of symbols . We illustrate here the generalization for Huffman coding.
Procedure:
Arrange the probabilities in descending order
Forward pass:
Add together the last symbols, insert the sum into the list etc.
Important: at the final step must have remaining values. It maybe necessary to add virtual messages with probability 0 at the end of the initial list, in order to end up with exactly messages in the last step.
Backward pass:
Assign all symbols to each of the final messages, then go back step by step.
Example : blackboard
5.7Probability of symbols¶
Given a code with symbols , we can compute the probability of apparition of each symbol in the code.
The average number of apparitions of a symbol is:
where is number of symbols in the codeword of (e.g. the number of 0’s and 1’s in a binary codeword)
If we divide this to the average length of the code, , we obtain the probability of symbol :
These are the probabilities of the input symbols for the transmission channel, which play an important role in Chapter IV (transmission channels).
6Source coding as data compression¶
Many times, the input messages are already written in a binary code, such as the ASCII code for characters.
In this case, source coding can be understood as a form of data compression, by replacing the original binary codewords with different ones, which are shorter on average, thus using fewer bits in total to represent the same information.
This process is similar to removing predictable or unnecessary bits from a sequence, We thus reducing the redunancy of the original data. The resulting compressed data appear random and patternless.
To obtain the original data back, the decoder must undo the coding procedure. If there were no errors during the transmission, the original data is recovered exactly. This makes it a lossless compression method.
As a final note, we mention that other coding methods do exist beyond Huffman coding, which provide better results (arithmetic coding) or other advantages (adaptive schemes).