1Exercise 1¶
Consider the binary codes below:
| Message | Code A | Code B | Code C | Code D | Code E | Code F |
|---|---|---|---|---|---|---|
| 00 | 0 | 0 | 0 | 0 | 0 | |
| 01 | 10 | 01 | 100 | 110 | 10 | |
| 10 | 110 | 011 | 11 | 10 | 11 | |
| 11 | 1110 | 0111 | 110 | 111 | 110 |
For each code:
a). Verify the Kraft inequality
b). Determine if the code is instantaneous / uniquely decodable
c). Draw the graph
1.1Solution¶
Let’s analyze a) and b) for each code.
The Kraft inequality is:
where is the length of the -th codeword.
Code A. For the first codeword, all 4 codewords have length 2, so the sum is:
The code is instaneaneous because no codeword is a prefix of another codeword. This means it is also uniquely decodable.
Code B. For the second codeword the lengths are 1, 2, 3, 4, so the sum is:
The code is instaneaneous, so it is uniquely decodable.
Code C. For the third codeword the lengths are also 1, 2, 3, 4 so the sum is the same as before.
The code is not instantaneous because the codeword for is a prefix of all the other codewods. However, the code is uniquely decodable, because of the following argument: each 0 marks the begining of a codeword, so given any binary sequence there will be no problem splitting it into codewords, because we just have to look for the 0s.
Code D. For the fourth codeword the lengths are 1, 3, 2, 3, so the sum is:
The code is not instantaneous because the codeword for is a prefix of the codeword for . It is also not uniquely decodable, because of the following argument: given the sequence 110, we can’t tell if it is or .
Code E. For the fifth codeword the lengths are also 1, 3, 2, 3, so the sum is the same as before.
The code is instantaneous, so it is uniquely decodable.
Code F. For the sixth codeword the lengths are 1, 2, 2, 2, so the sum is:
The code is not instantaneous nor uniquely decodable, because no code with these four lenghts can ever be, since the Kraft inequality is violated.
c). The graphs for the codes are represened below.
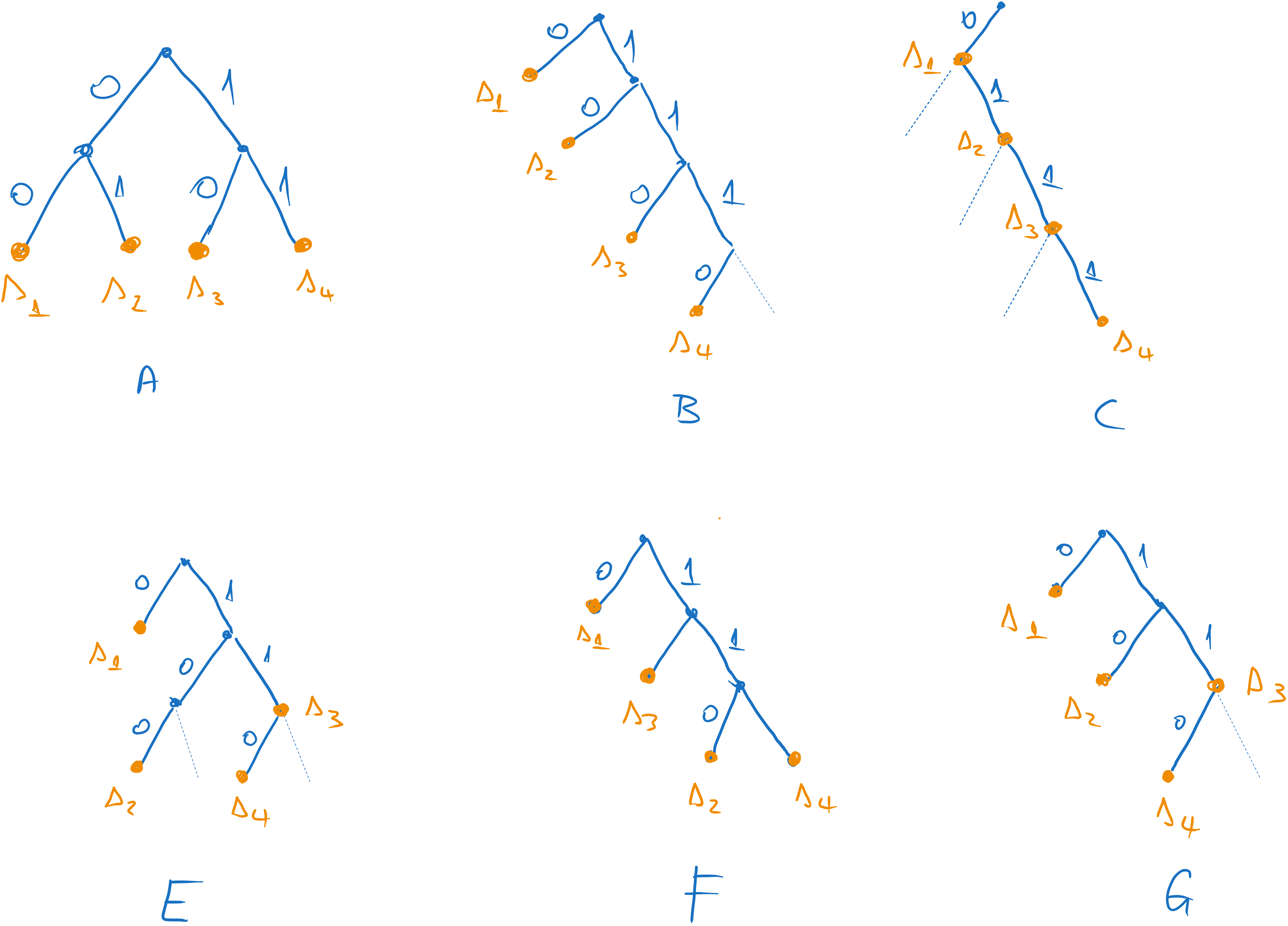
Figure 1:The graphs of the codes A, B, C, D, E, and F.
2Exercise 2¶
Consider a memoryless source with the following distribution:
For this source we use two separate codes:
| Message | Code A | Code B |
|---|---|---|
| 00 | 0 | |
| 01 | 10 | |
| 10 | 110 | |
| 11 | 111 |
Requirements:
a). Compute the average lengths of the two codes
b). Compute the efficienty and redundancy of the two codes
c). Encode the sequence with each code
d). Decode the sequence
011010101010111100001010with each code
2.1Solution¶
a) Compute the average lengths of the two codes¶
The average length of a code is given by:
where is the probability of the -th message and is the length of the codeword for the -th message.
For Code A, we have:
For Code B, we have:
b) Compute the efficienty and redundancy of the two codes¶
We need first to compute the entropy of the source.
Therefore the efficiency of Code A is , and the (relative) redundancy is .
For Code B, and .
c) Encode the sequence with each code¶
We just replace the messages with their codewords, according to each code.
With Code A we get:
With Code B:
d) Decode the sequence 011010101010111100001010 with each code¶
We need to identify the codewords in the sequence and replace them with the corresponding messages.
With Code A we get

Figure 2:Decoding with the first code
With Code B we get:

Figure 3:Decoding with the second code
3Exercise 3¶
Fill in the missing bits (marked with ?) such that the resulting code is instantaneous.
| Message | Codeword |
|---|---|
(just replace the ‘?’; do not add additional bits)
3.1Solution¶
This is a creative exercise. We don’t have a fixed algorithm to solve it, but we can try to find a solution by trial and error. Note that since the code is instantaneous, no codeword can be a prefix of another codeword.
For example, we observe that we have three codewords with lengths 2, which will occupy three quarters of the graph. This means that the codewords for and , which have length 3, must both stem from the same node (have the same two bits). Thus, we can choose:
The other codewords occupy all other combinations of two bits (00, 01, 10), for example:
4Exercise 4¶
We perform Shannon coding on an information source with b.
a. What are the possible values for the efficiency of the code?
b. What are the possible values for the redundancy of the code?
c. What is the minimum number of messages the source may possibly have?
4.1Solution¶
a. What are the possible values for the efficiency of the code?¶
We know that if we do Shannon coding, the average length of the resulting code is between and :
This means the efficiency, which is , is between:
which means
b. What are the possible values for the redundancy of the code?¶
The relative redundancy is , so it is between 0 and 0.05.
The absolute redundancy is , so it is between 0 and 1.
4.2c. What is the minimum number of messages the source may possibly have?¶
Because the entropy of the source is 20 bits, this means the source has many messages.
Remember one of the properties of entropy, that it is maximum when all messages are equally probable, and in this case the entropy is , where is the number of messages:
Out source has an entropy of bits, so the maximum entropy is at least 20 bits. We have:
which means , so the source must have at least messages in order to be possible to have an entropy of 20 bits.
5Exercise 5¶
A discrete memoryless source has the following distribution:
a. Encode the source with Shannon, Shannon-Fano coding and Huffman coding and compute the average length in every case.
b. Find the efficiency and redundancy of the Huffman code
c. Compute the probabilities of the symbols 0 and 1, for the Huffman code
5.1Solution¶
a. Encode the source with Shannon, Shannon-Fano coding and Huffman coding and compute the average length in every case¶
The three coding methods are explained below.
Shannon encoding:
We arrange the probabilities in descending order:
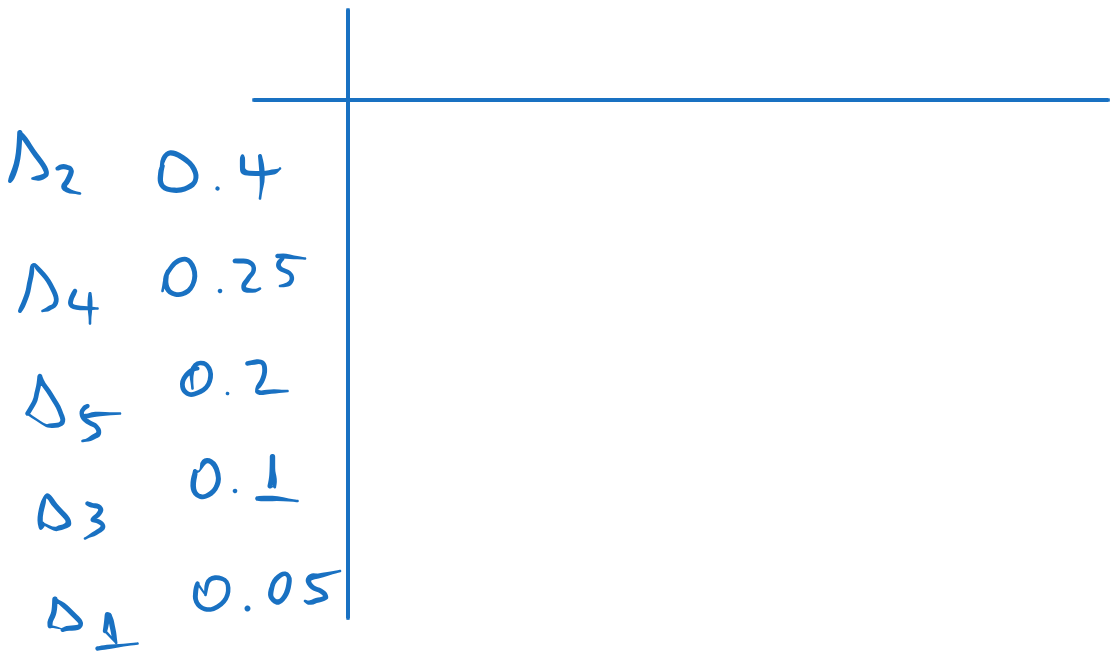
We compute the codeword lenghts with , where means “rounding upwards”:
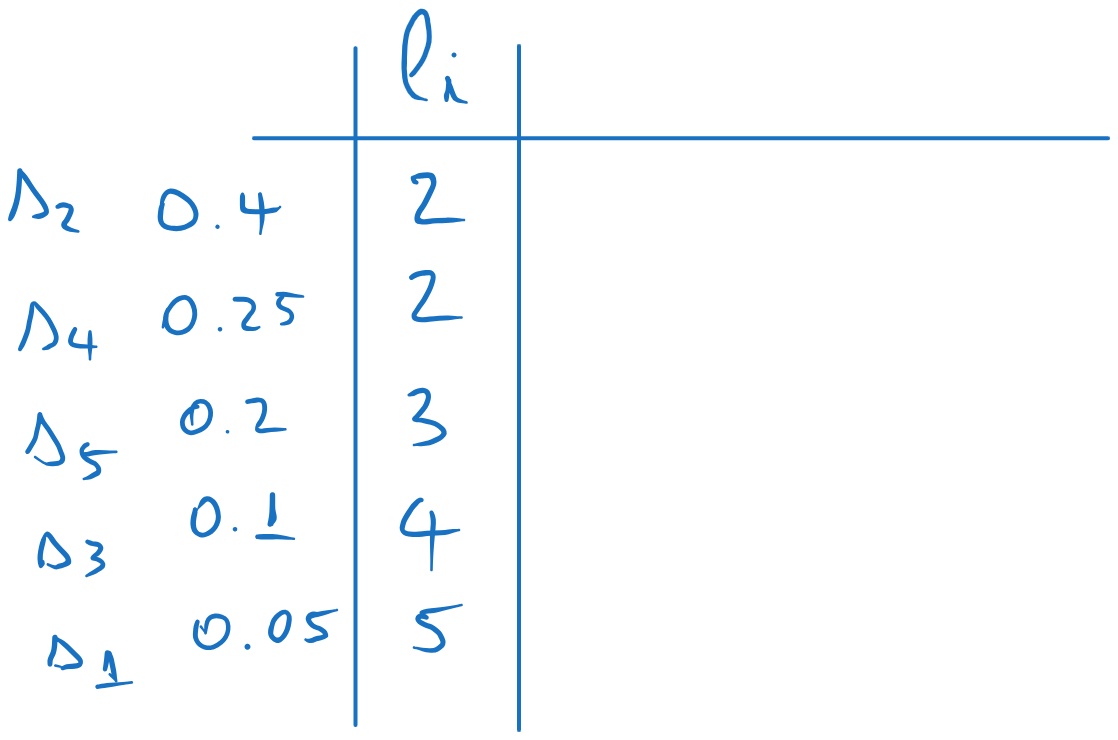
We compute the cumulative sum probabilities, i.e. the sum of the probabilities up to the current row, but not including the current row:
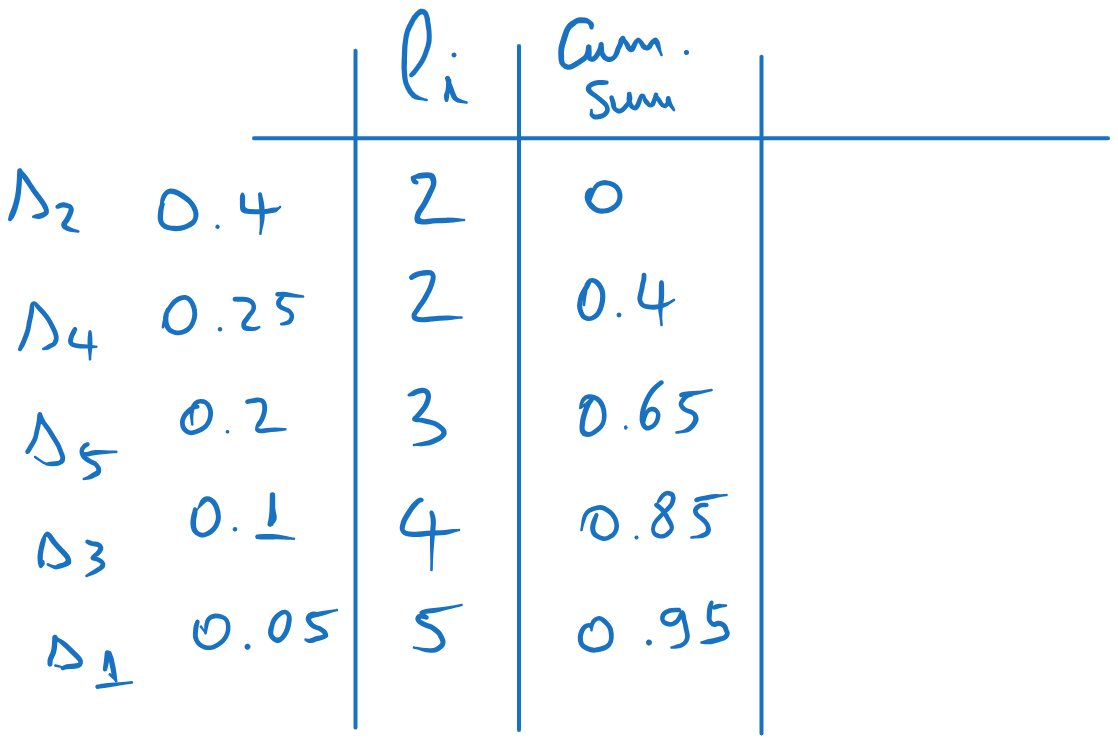
We find the codewords as follows, adding another three columns:
4.1 Compute the values (the cumulative values multiplied by , rounded downwards). 4.2 Write these values in binary, using bits. If there are less bits than , add zeros to the left. These are the codewords,
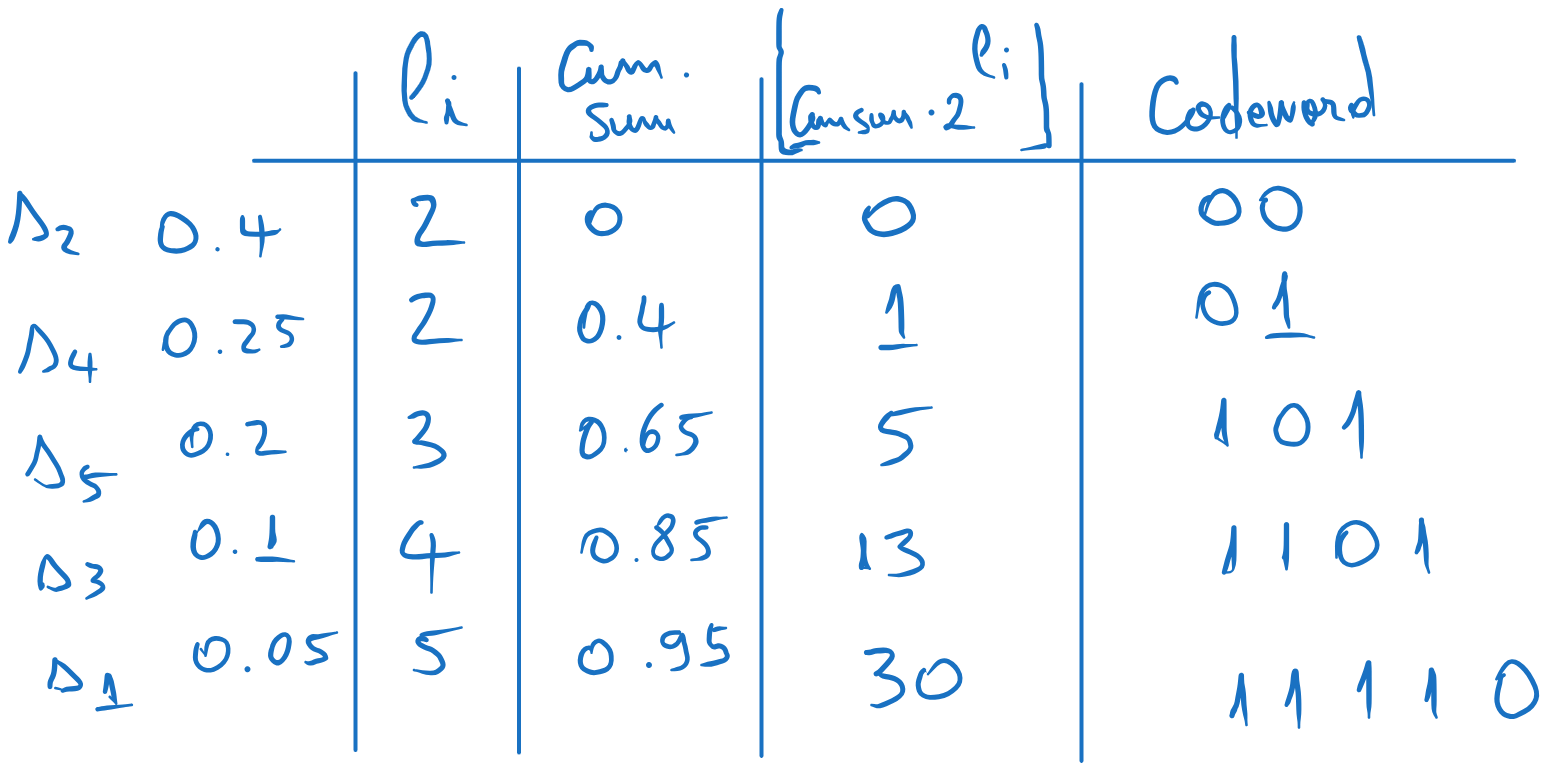
Figure 6:Obtaining the codewords using Shannon coding
Shannon-Fano coding:
We arrange the probabilities in descending order:
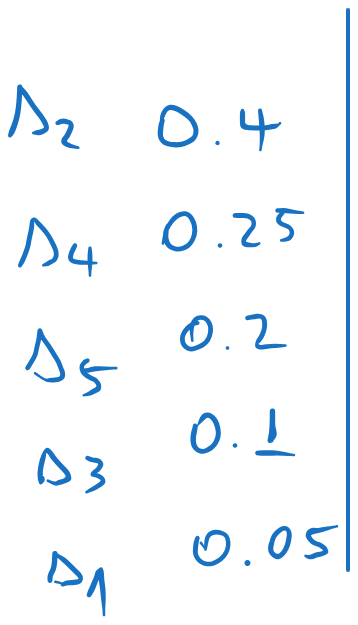
We split the list in two, such that the sum of the probabilities in each part is as close as possible (i.e. as close as possible to ). We assign 0 to one part and 1 to the other.
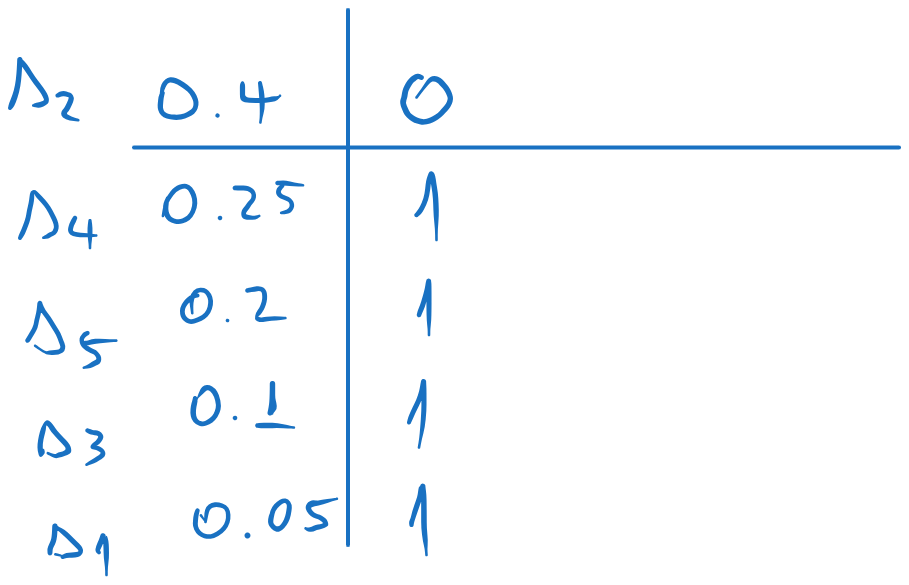
We repeat the process for each sub-list, splitting each in two as close as possible and assigning 0 and 1 to each sub-part.
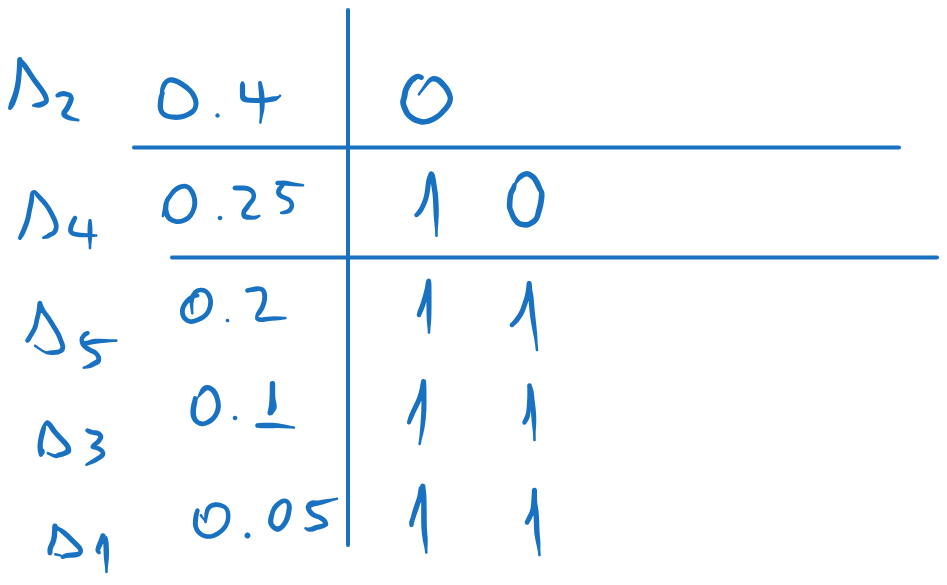
We continue until we have only one element in each sub-list. Each element will have the corresponding codeword.
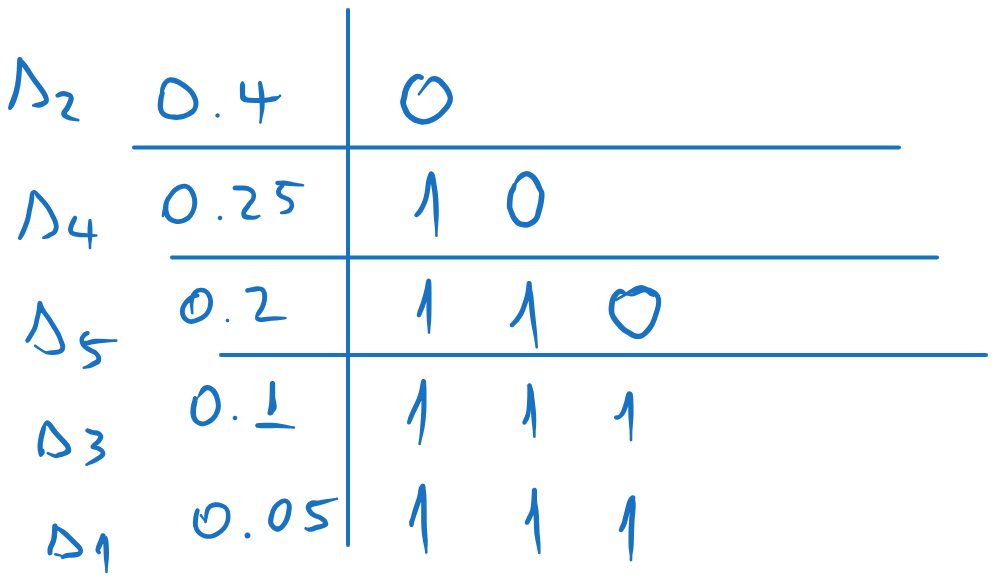
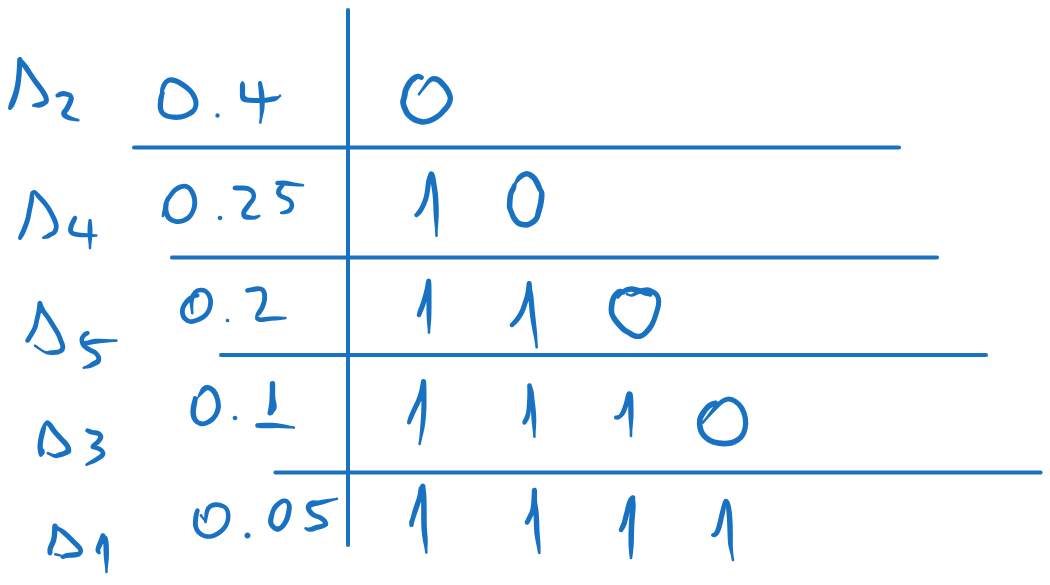
Figure 12:Codewords obtained with Shannon-Fano coding
Huffman coding:
We arrange the probabilities in descending order:
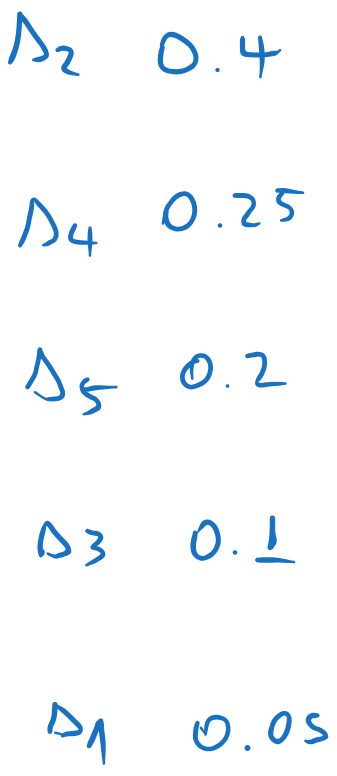
We sum the messages with the lowest probabilities, and we insert the sum in the list, keeping the list sorted. All other messages are kept in the same order. In this case, the combined message ends at the bottom of the list.
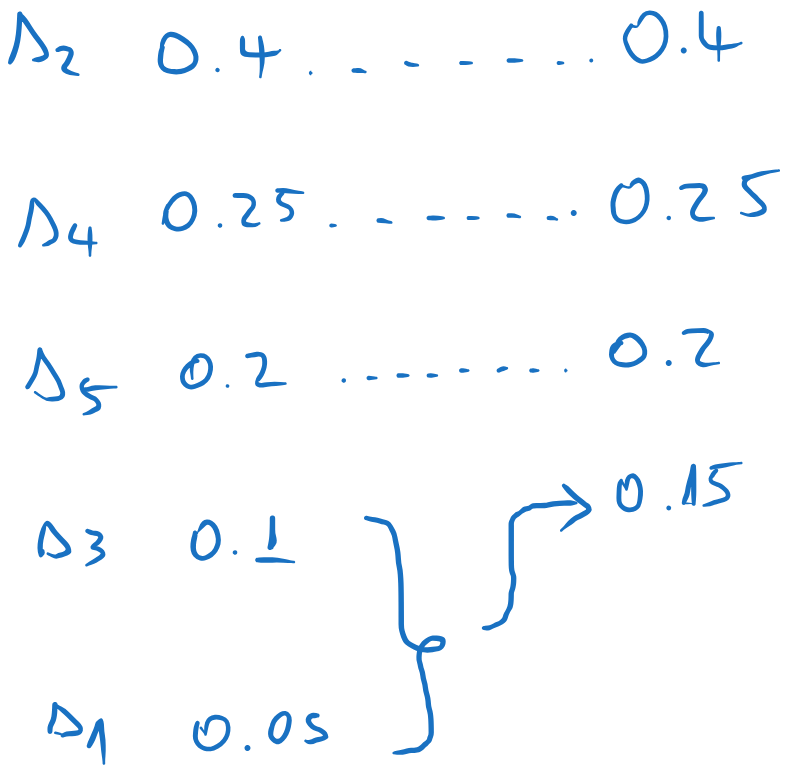
We repeat the process until we have just two elements. Every time we add the last two elements, and we insert the result among the other elements, keeping the list sorted.
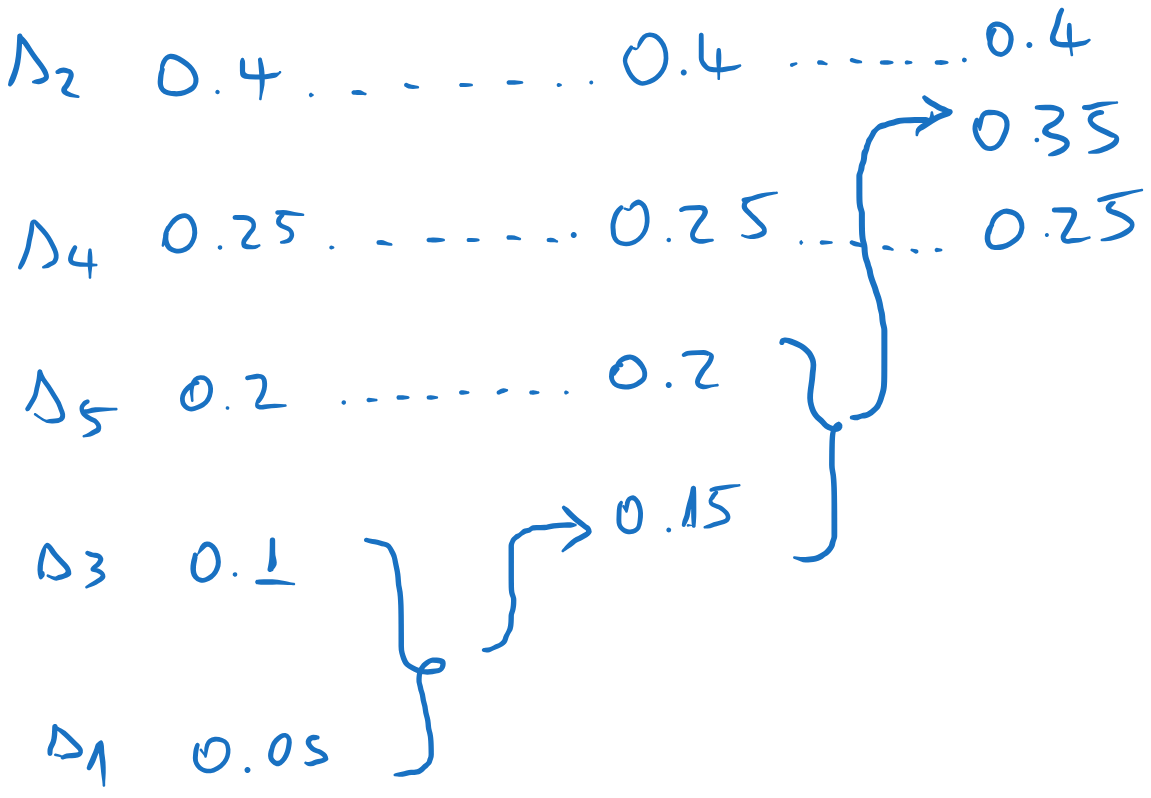
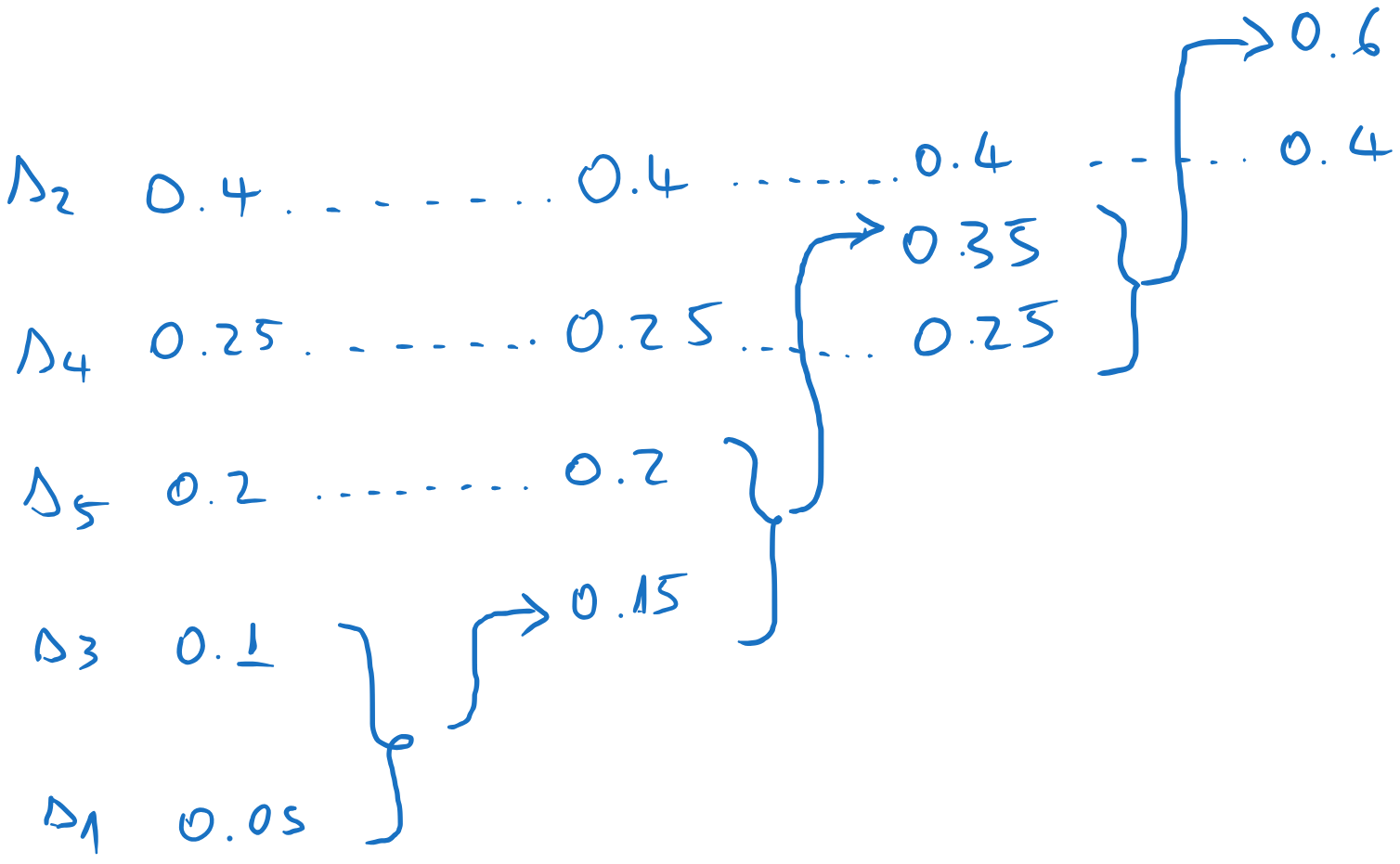
Now we start the backward pass. We assign 0 and 1 to the final two messages
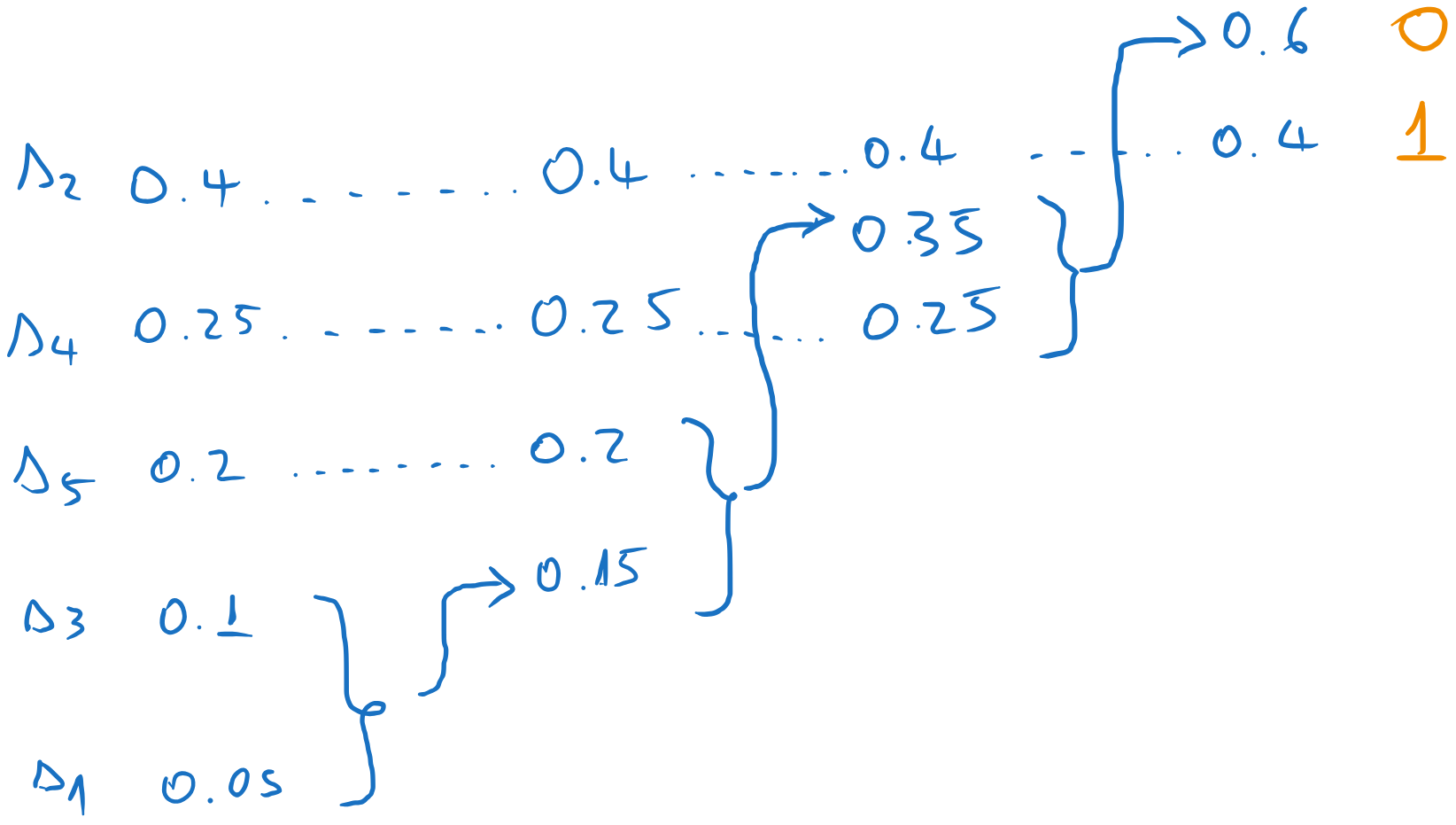
We go one column to the left, and we assign codewords to the two messages which were combined in the previous step. The codewords inherit the codeword of the parent (0), to which we append an extra 0 and 1.
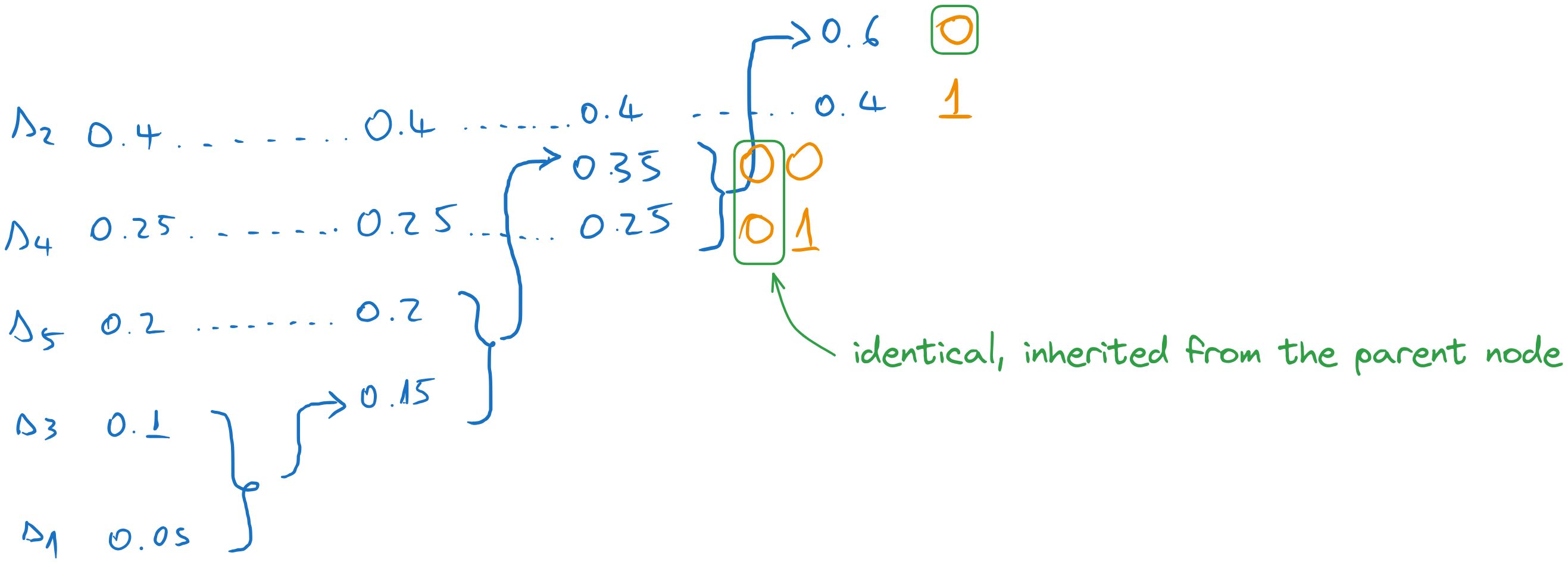
We continue until we reach the first column. Every time we take the codeword of the parent and we append a 0 and a 1 to form the codewords of the combined messages. All other messages just inherit the previous codeword.
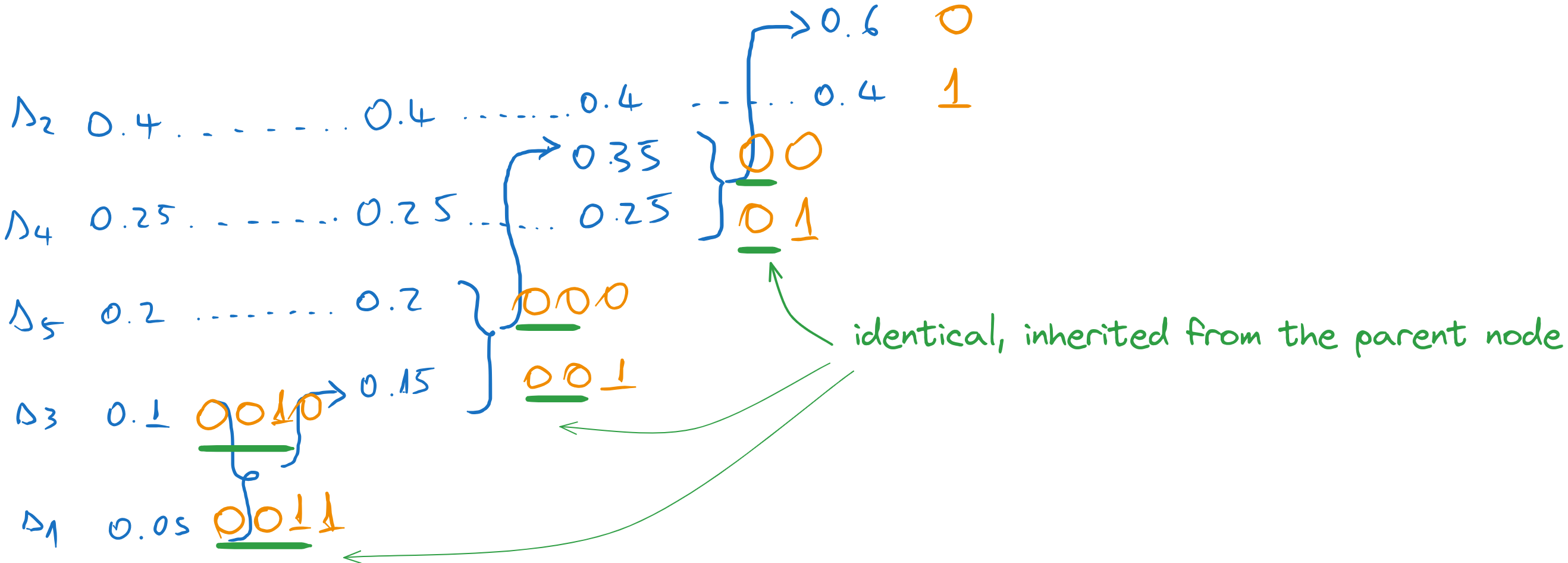
In the end, we read the codewords of each message along the lines.
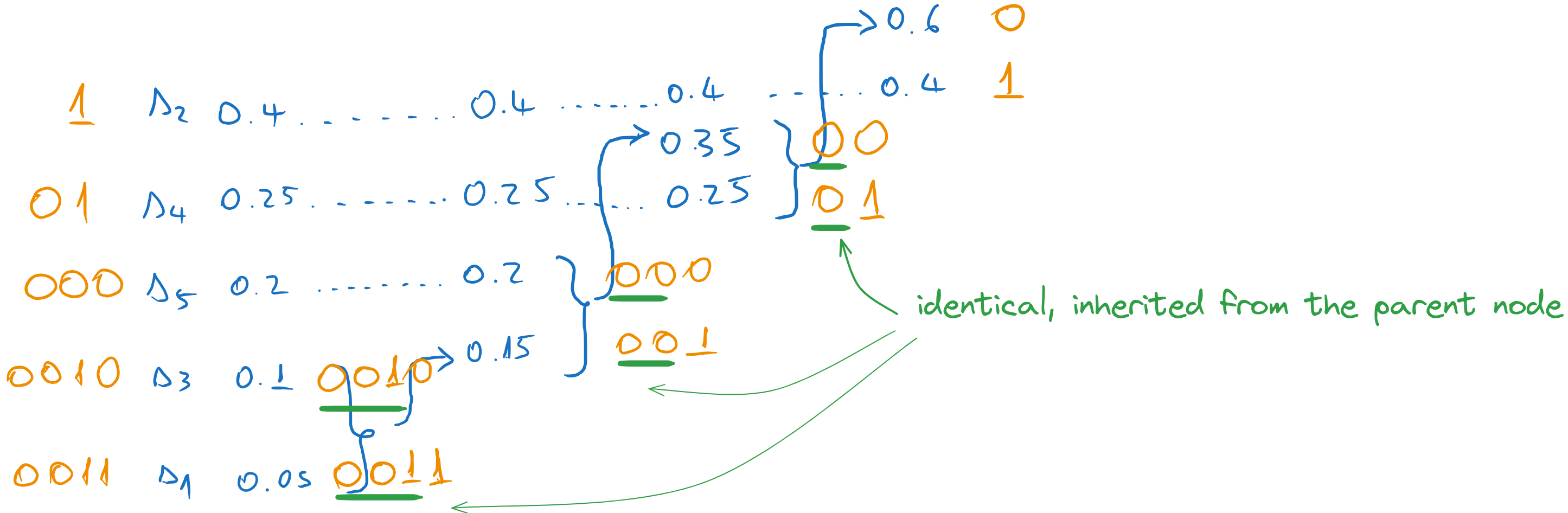
Figure 20:Codewords obtained with Huffman coding
Once we have the codewords, we can compute the average length of the code:
where is the probability of the -th message and is the length of the codeword for the -th message.
For the Shannon code, we have:
For the Shannon-Fano code, we have:
For the Huffman code, we have:
b) Find the efficiency and redundancy of the Huffman code¶
We need first to compute the entropy of the source.
The efficiency of the Huffman code is
The relative redundancy is , and the absolute redundancy is bits.
c) Compute the probabilities of the symbols 0 and 1, for the Huffman code¶
We need first to compute the average numbers of 0’s and average number of 1’s in the codewords, and . We compute them just like the average length, but we consider only the number of 0’s and 1’s in the codewords, not the full codeword lenghts.
We have:
Note that .
The probabilities of 0 and 1 are:
This means that 0’s predominates in the codewords.
6Exercise 6¶
For the following source, perform Huffman coding and obtain two different codes with same average length, but different individual codeword length.
Compute the average length in all three cases and show it is the same.
6.1Solution¶
Huffman codes with the same average length but different individual codeword lengths are obtained when the sum of the probabilities of the two least probable messages is the same as some other values in the list, such that we can place the result in different positions in the list.
Let us start Huffman coding on this source. At the second step, we obtain a combined message with probability 0.25, which could be inserted in several positions in the list.
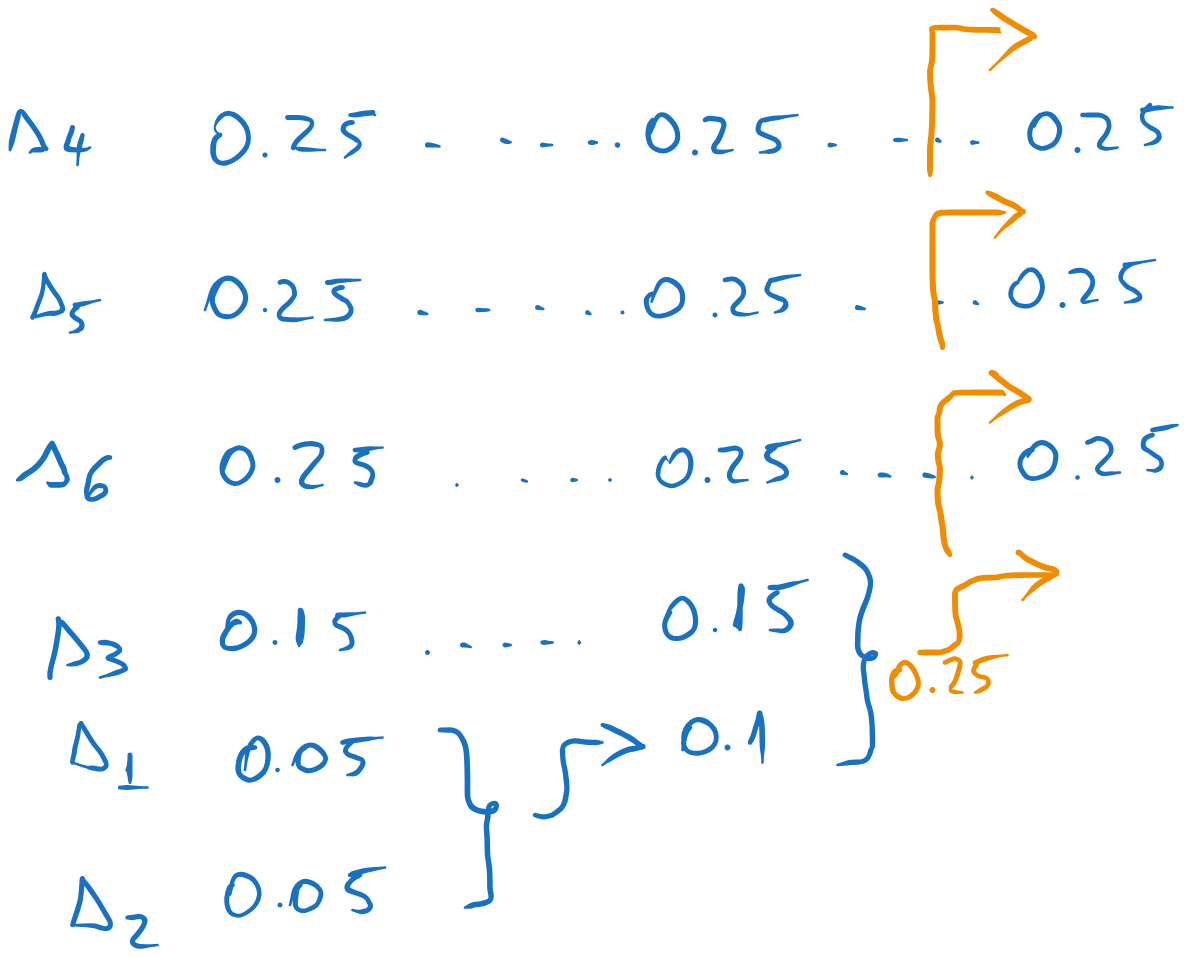
Figure 21:Different placement options.
Each of the four options will lead to a slightly different code, but with the same average length, but with possibly different individual codeword lengths.
Let us proceed with three different cases and compute the average length in each case.
Variant 1
Suppose we choose the lowest position for the combined message. Continuing the process, we obtain the following codewords:
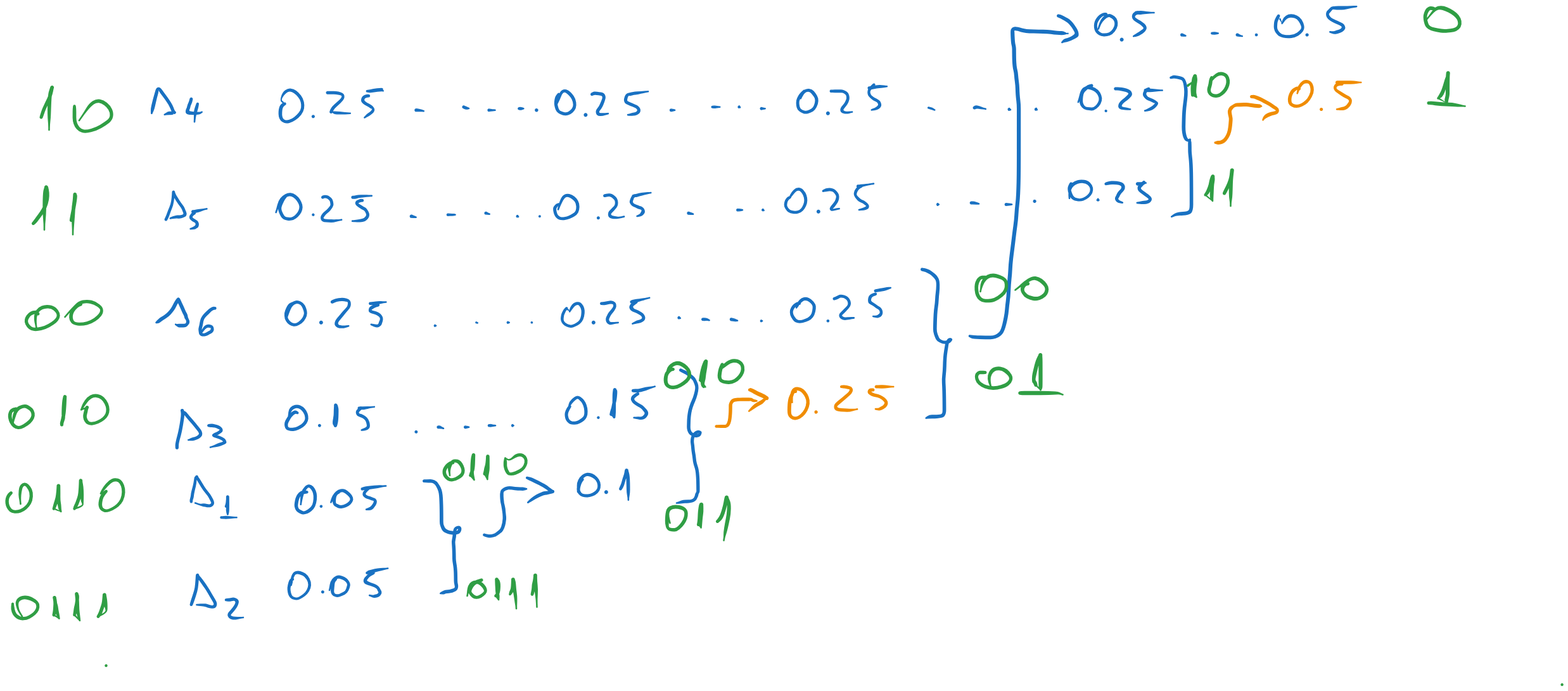
Figure 22:Codewords for the first variant.
Note that we also had another option to choose for the 0.5 value, but this one has little impact on the final result, because it is close to the end.
The average codeword length is:
Variant 2
Suppose we choose instead the highest position for the combined message. We obtain:
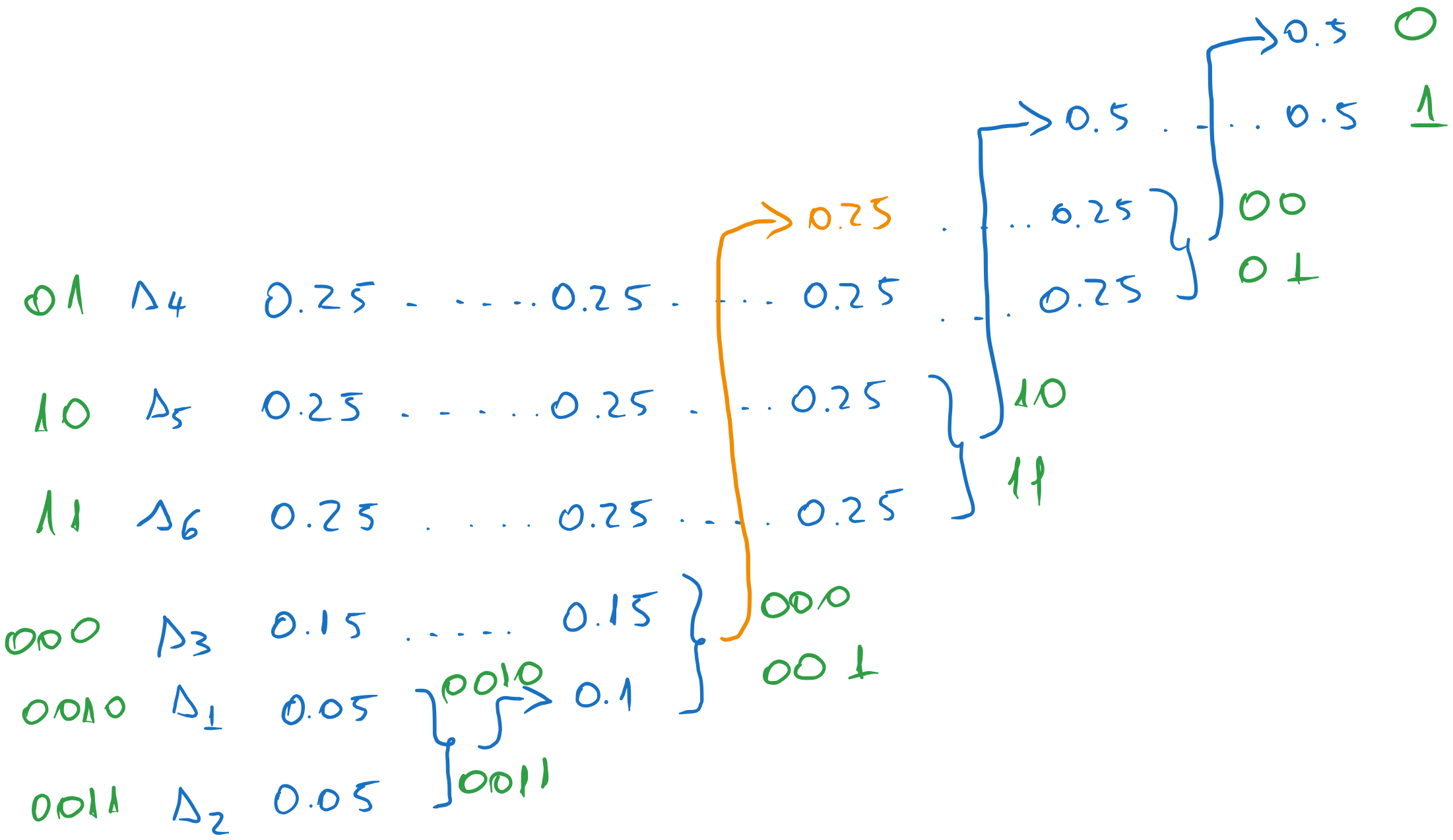
Figure 23:Codewords for the second variant.
In fact, the codeword lengths are the same as in the previous case, because the list of messages is small. If we had an example with many more messages, the codeword lengths would have been different.
The average codeword length is the same:
7Exercise 7¶
A discrete memoryless source has the following distribution:
a). Find the average code length obtained with Huffman coding on the original source and on its second order extension.
b). Encode the sequence with both codes.
7.1Solution¶
a). Find the average code length obtained with Huffman coding on the original source and on its second order extension.¶
For the original source, we have the following coding process:
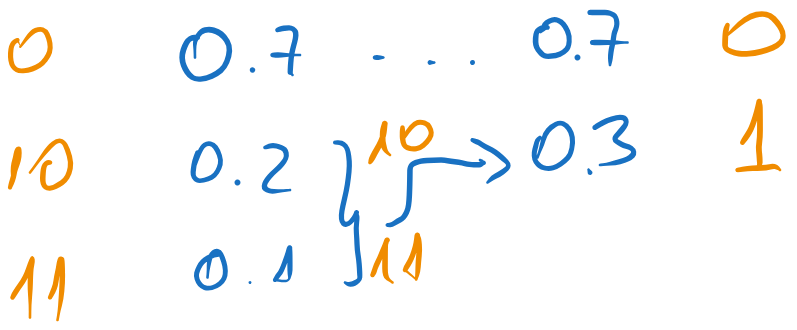
Figure 24:Huffman coding of the original source
The average length is:
The second order extension is obtained by considering all possible pairs of messages:
The Huffman coding is:
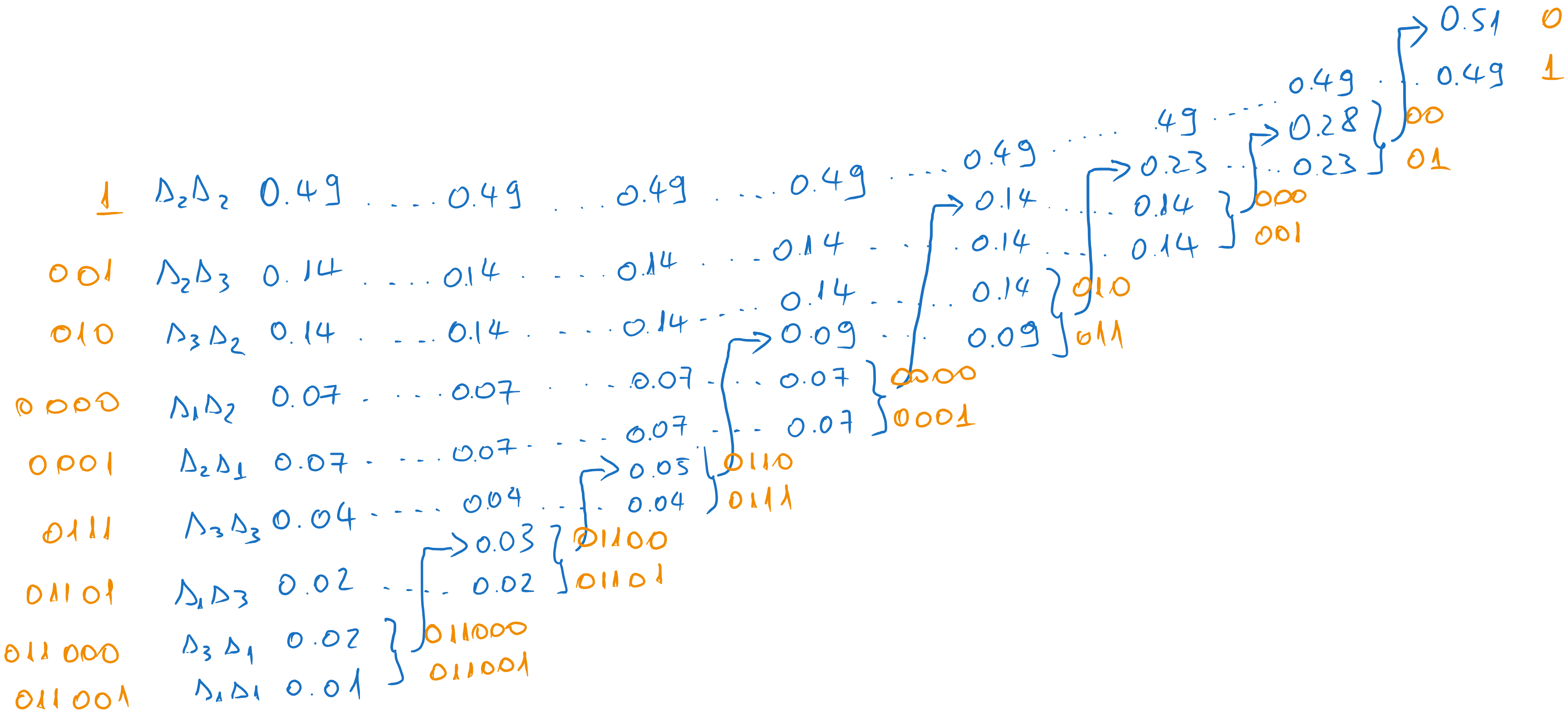
Figure 5:Huffman coding of the second order extension
The average length is:
Note that the second order extension is more efficient than the first, because it is better to encode a pair of messages with 2.33 bits on average than each message with 1.3 bits on average.
b). Encode the sequence with both codes.¶
With the first code, we encode each individual message:
With the second code, we encode each pair of messages with its codeword:
8Exercise 8¶
A discrete memoryless source has the following distribution
Find the Huffman code for a code with 4 symbols, , , and , and encode the following sequence:
8.1Solution¶
For the Huffman code with 4 symbols, we combine the last 4 messages in the list.
The Huffman coding proceeds as follows:
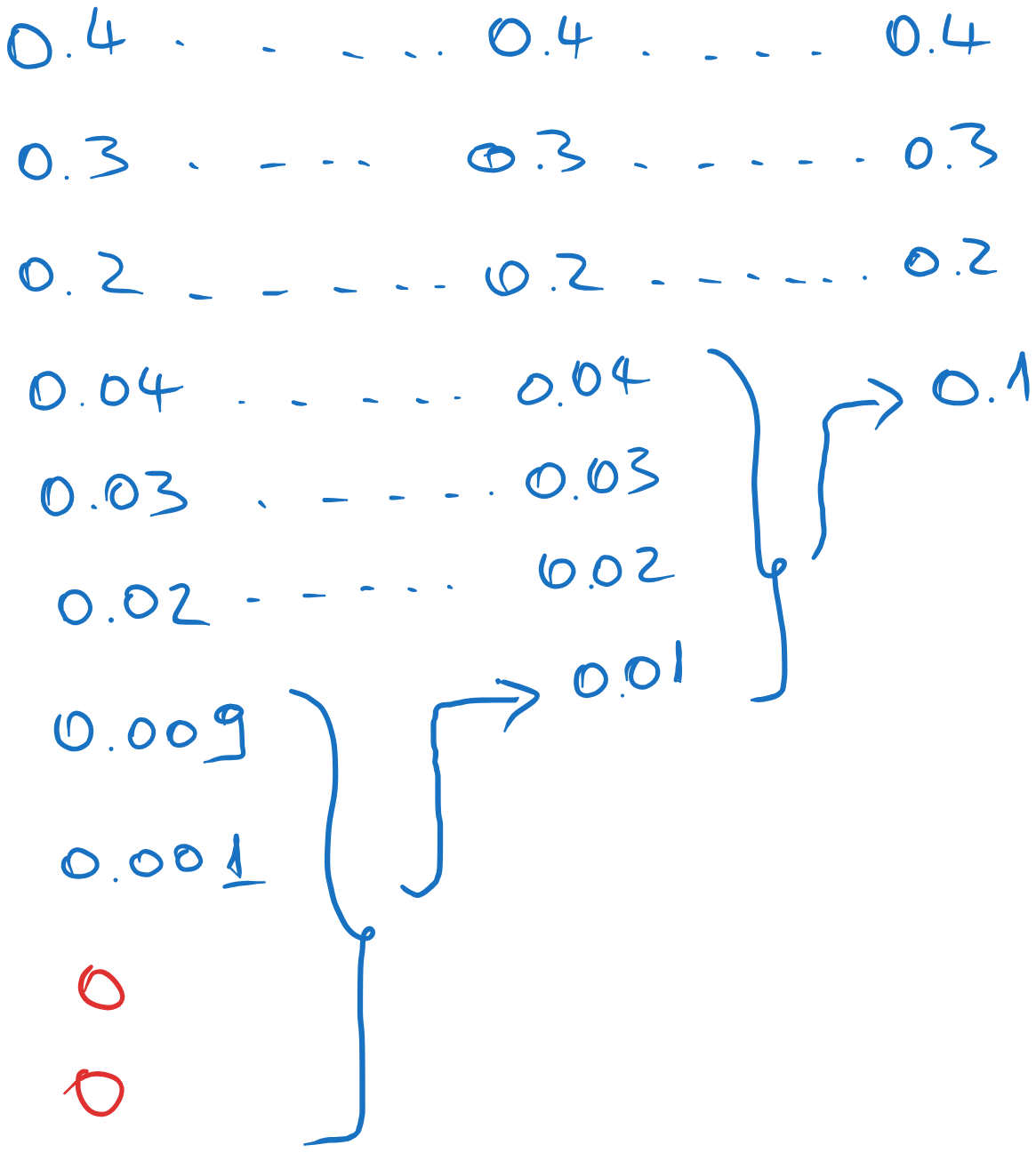
Figure 26:Huffman coding of the source
At the backward pass, we assign the symbols , , and from right to left:
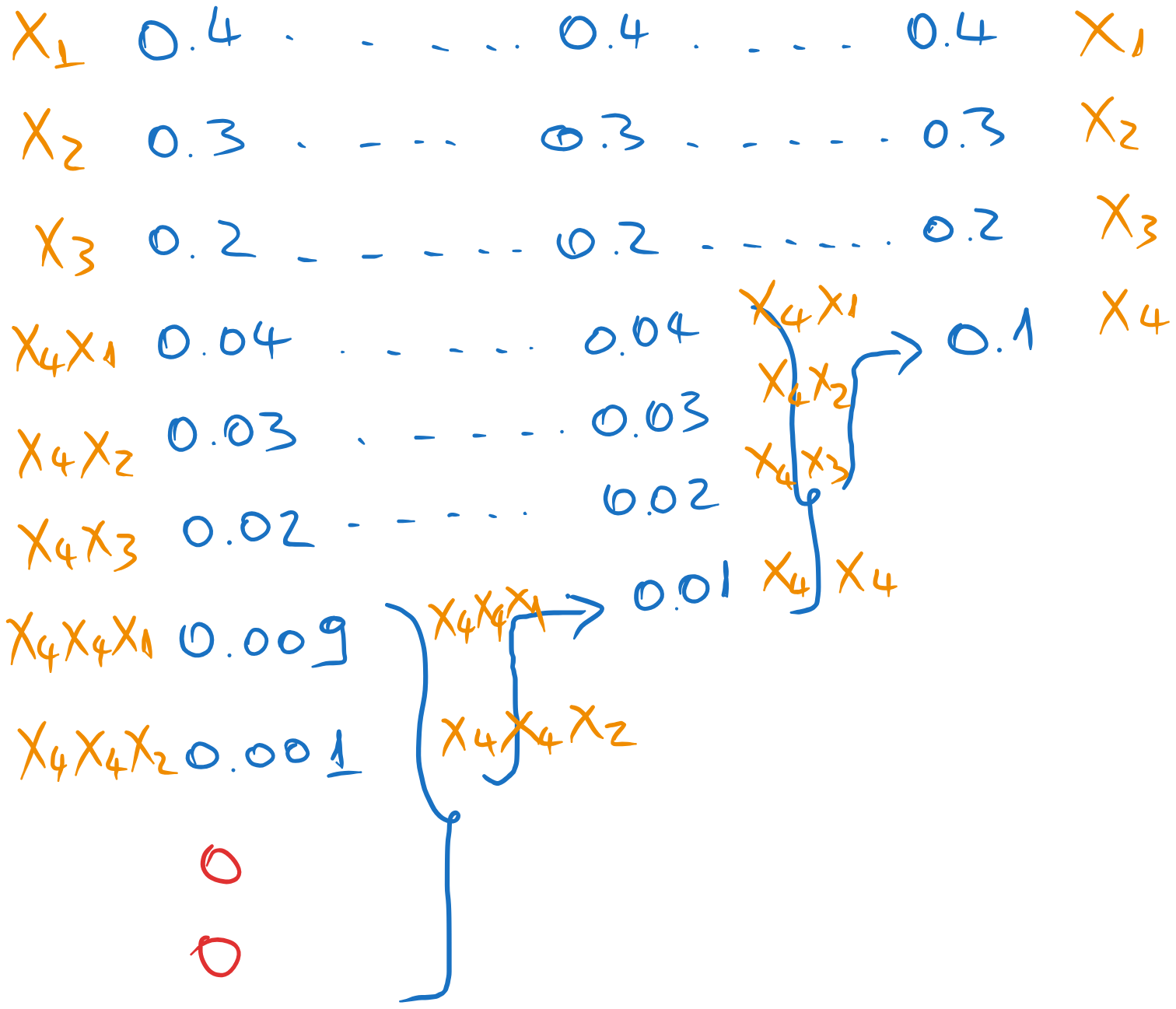
Figure 27:Assigning the symbols
The average length of the code is:
The sequence is encoded as: